
RAG Isn’t Dead. You Just Outgrew Naive Retrieval.


I have been reading, especially lately, many "think pieces" on how RAG (Retrieval Augmented Generation) is "dead", "ngmi", and other meme-worthy superlatives. This blog is likely to be very pedantic, and focus on small but important clarifications of language. So STRAP IN folks.
Let's get this out of the way early on: TL;DR: RAG isn’t dead. What’s dying is Naive RAG - dense vector lookups glued to a prompt. That’s good. We’ve evolved. Most of this discourse is borne of RAG undergoing a very specific kind of semantic diffusion.
You may attempt to blame the original RAG paper - but we immediately abandoned their definition of RAG.
More broadly (and correctly), RAG is simply the augmentation of a generators context through a retrieval process. Slapping the word "Agentic" onto the 'R' in RAG doesn't make it less "RAG-y", it just means you've progressed beyond what I (among others) refer to as "naive RAG". Which is good, and should be celebrated - here's a cookie. 🍪
NOTE: Jerry Liu at LlamaIndex has a banger blog on exactly this - ending with a great line: Naive RAG is dead, agentic retrieval is the future
In additional to naive RAG, which we're going to use to refer to dense vector retrieval backed RAG for the rest of this blog, there exists a number of various "flavours" of RAG, from hybrid search, to GraphRAG, and of course - Agentic Retrieval backed RAG, typically shortened to "Agentic Retreival".
🐱Naive RAG - Dense vector search only
🧪Hybrid RAG - Dense + sparse
🧠Agentic RAG - Model navigates context dynamically
🕸️Graph RAG - Link-aware retrieval
"But, Chris!", I hear you shouting, " the Claude Code team said they dropped RAG for agentic discovery!".
tl;dw - indexing is not it for working in fast changing code-bases
And they did, but if you listen to the system they describe - you'll find that they are clearly referring to dense vector retrieval. If pressed on it, I'm sure they'd agree that they are still doing retrieval - it's just not backed by a vector database. You'll also notice the ever present cost trade-off slip by unnoticed in the conversation:
"At the cost of latency and tokens, you know have really awesome search - without security downsides".
Sure, people have different tolerances for latency and tokens (time, and money, respectively) - but it is a massively understated part of the discussion that is often handwaved away by hyperbole by the side advocating for purely agentic approaches.
As for quality, from the video above - the decision to switch was largely based on vibes, which in no way is indicative of the evaluation crisis we're currently in...
If you're building a coding agent, you should seriously consider RAG
SWE-Bench isn't the be-all-end-all of benchmarks, but it's still pretty tight, and it tells an interesting story about RAGs place in the world of autonomous coding agents.
For instance:
Refact.ai's recent leaderboard topping SWE-Bench Agent leverages "traditional" RAG in a number of components (both sparse and dense vector retrieval) to achieve its impressive 70.4%.
In a close second place (also achieving 70.4%) is the OpenHands agent workflow, which utilizes keyword retrieval for it's memory system.
As an aside, OpenHands is overleraging test-time scaling (inference-time scaling) to achieve their great results.
The current 3rd place solution only uses search, and does not directly use any dense vector retrieval system in any part of its flow, only agentic retrieval/search. (score one for the haters)
Coming in at a 4th place (by unique architecture) Augment Agent v0 finds that, while grep and find are good enough for SWE-Bench; "In practice, we find that embedding-based tools are critical to deliver a great product experience."
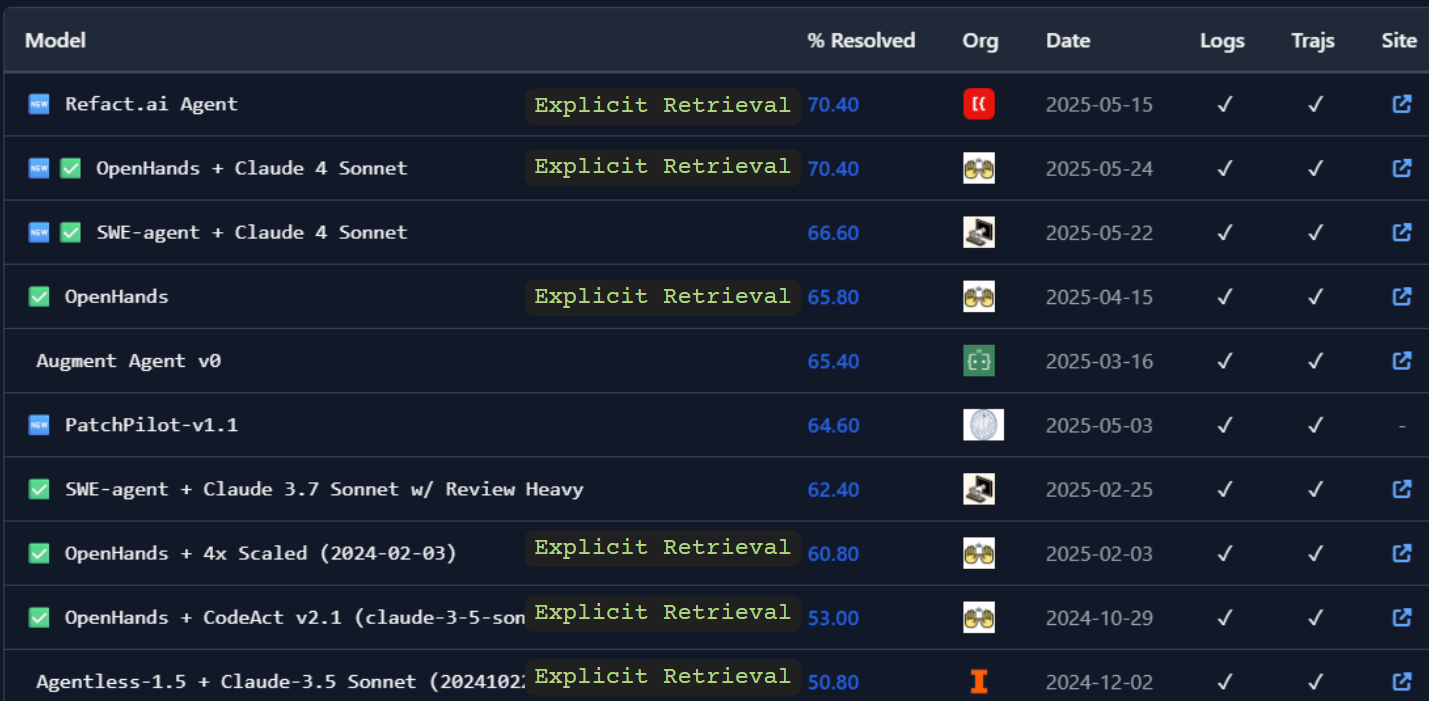
Is this definitive proof that coding agents need naive RAG to work? No. Is it good signal that naive RAG remains useful for these applications? I'd say so.
This is a minor point, and extends into non-naive RAG as well, but the most popular autonomous agents (Jules, Windsurf, Cursor, Codex) are leveraging RAG on the daily - there's probably some signal there.
RAG is cheap, seriously.
Large-context-window models, despite being powerful, have significant cost and latency issues. Processing extensive context each time can be prohibitively expensive and slow. In contrast, RAG efficiently provides high-quality, targeted pieces of context, drastically cutting inference costs and latency while maintaining or even improving solution quality.
Lost in the Middle is being lost from our minds just because NIAH charts look good these days
Evaluating and improving RAG systems is fairly well understood, and cheap. Building a "data flywheel" for your autonomous system is a powerful pattern that can help bring RAG to the next level in a way that is currently not "solved" (loosely) for non-retrieval based systems.
RAG isn't dead. It's one of the many tools you can leverage for coding.
At the end of the day, the whole blog could've been - in all caps comic sans, of course - "RAG IS MORE THAN JUST DENSE VECTOR RETRIEVAL", but I hope this helped clear some things up, and showcase the relevance of dense vector retrieval - even in 2025 and even for a use-case it is supposedly not good at.
Call it RAG, call it search, call it “agentic spelunking” - just don’t pretend your agent isn’t doing it. Because it is.